Conversación con Gema Parreño

Gema es una programadora que ha diseñado Deep Asteroid, una red para detectar el impacto de asteroides sobre la tierra. El proyecto quedó finalista a nivel global en el concurso de la NASA International Space Apps Challenge 2016 y fue seleccionado como uno de los casos de uso por Google en la keynote Google I/O de 2017, y el framework TensorFlow en 2018. Ha realizado algunos desarrollos y es contribuidora en el proyecto de StarCraft 2 Pysc2 de Deepmind..
Aunque estudiaste Arquitectura has acabado desarrollando tu carrera profesional a medio camino entre el mundo de Data y los videojuegos. ¿Cómo fue esa evolución?¿ ¿En qué momento tuviste claro a qué querías dedicarte?
Acabé Arquitectura con la crisis del 2008. Por aquel entonces, me dedicaba con un grupo de compañeros a realizar concursos de vivienda, innovación, diseño y urbanismo. Dominábamos bastante el 3D y la idea de lanzarnos con estas herramientas al sector más tecnológico surgió de manera natural. Fundamos una Startup de animación y videojuegos con un proyecto que tuvo cierta tracción, llegando a una aceleradora .
En el año 2016, participaste en el NASA Space App Challenge y con otros participantes desarrollasteis Deep Asteroid, una red para detectar el impacto de asteroides sobre la Tierra. Vuestro proyecto consiguió clasificarse entre los veinticinco proyectos más innovadores de la edición y entre los cinco que mejor utilizaron los datos. Me gustaría que me contaras en qué consistía el proyecto: qué tipo de datos utilizasteis, qué métrica tratabais de optimizar y qué algoritmos y frameworks usasteis
Sobre los datos, NASA puso a disposición su dataset de impacto de Asteroides del que tiene registro con diferentes institutos astronómicos : filtramos en concreto aquellos que daban datos relevantes sobre los PHA ( Potential Hazardous Asteroids ) que incluían su clasificación entre los diferentes subgrupos ( Aten y Apolo ) con datos sobre el MOID ( Minimum Orbit Intersection Distance ).
Deep Asteroid es una arquitectura de red Neuronal que clasifica los asteroides en fecha y lugar de impacto. Utiliza varias capas que tienen en cuenta datos sobre su órbita y clase. Como principal framework , usamos TensorFlow , framework open source de Google, utilizado internamente primero dentro de su tecnología del buscador.
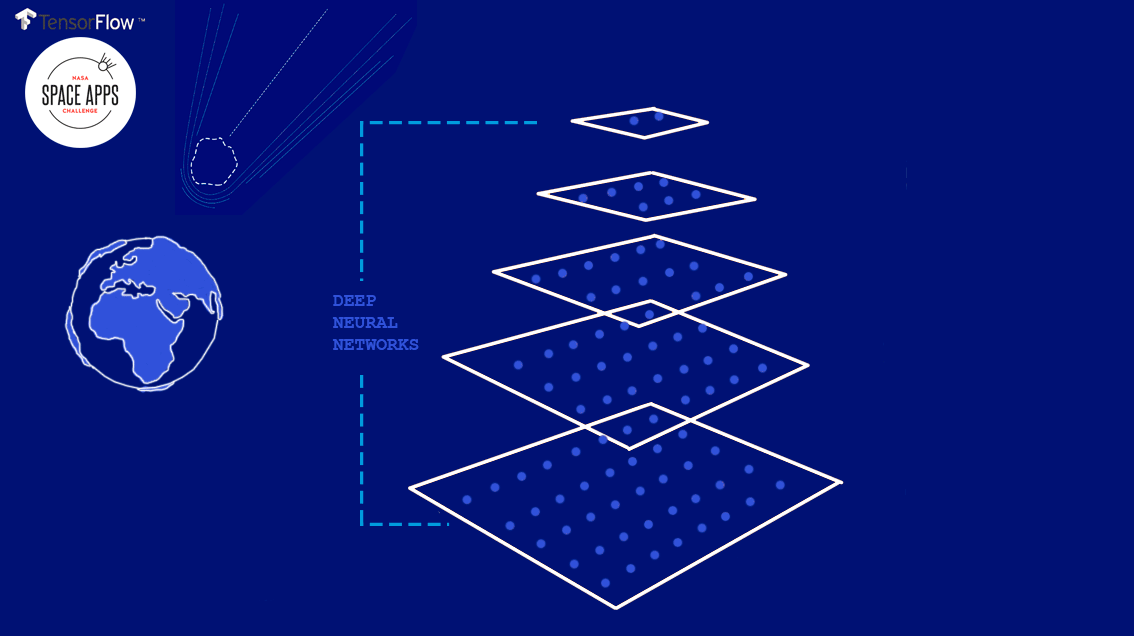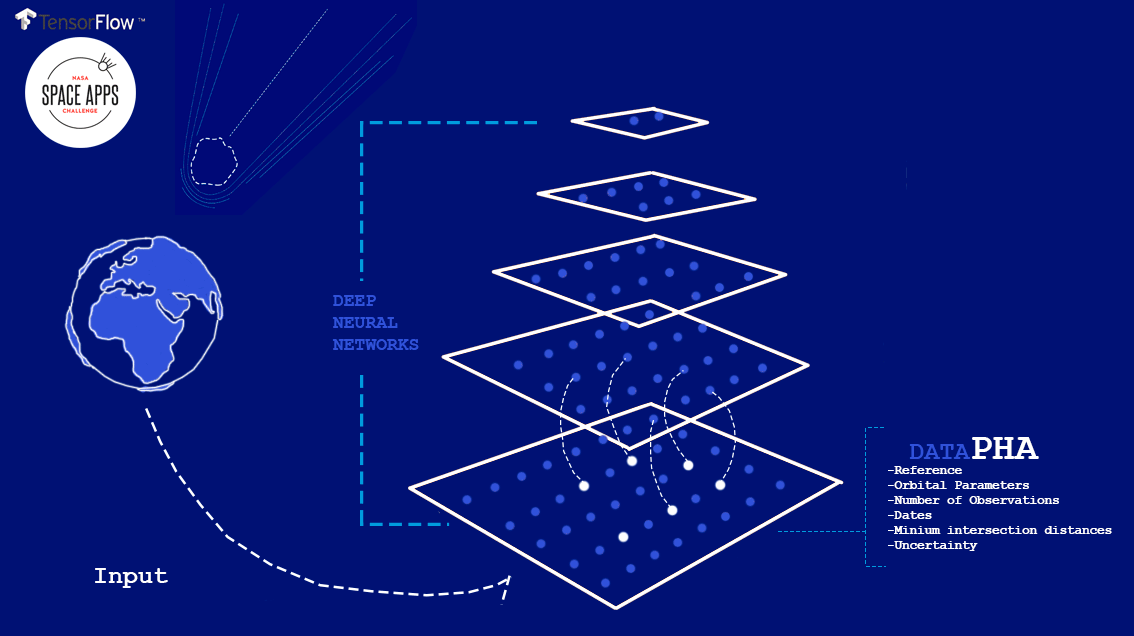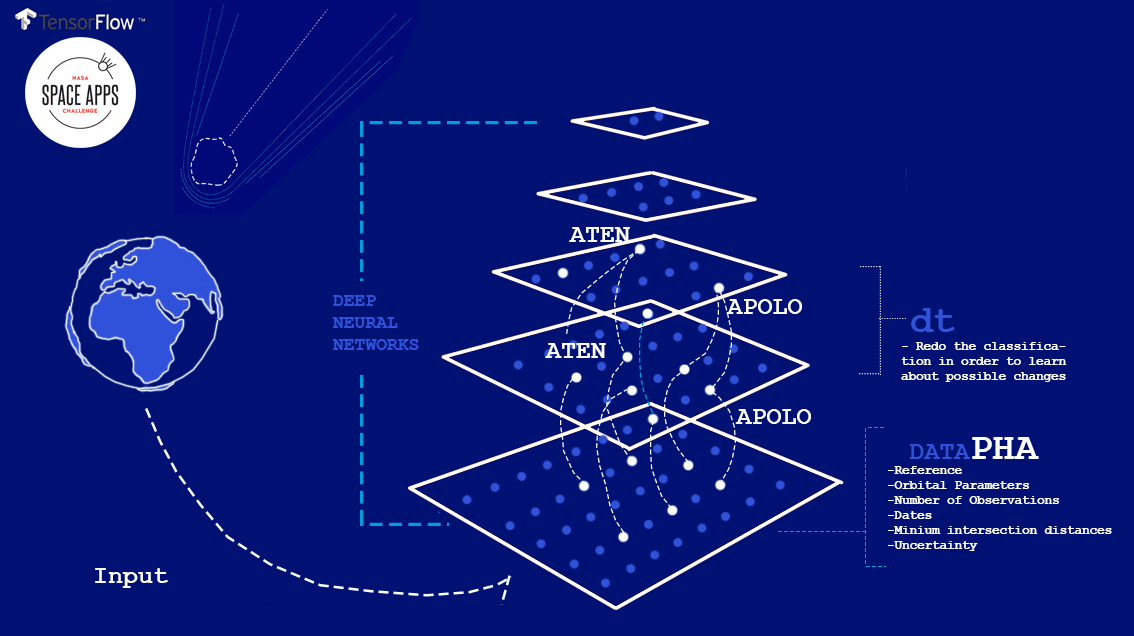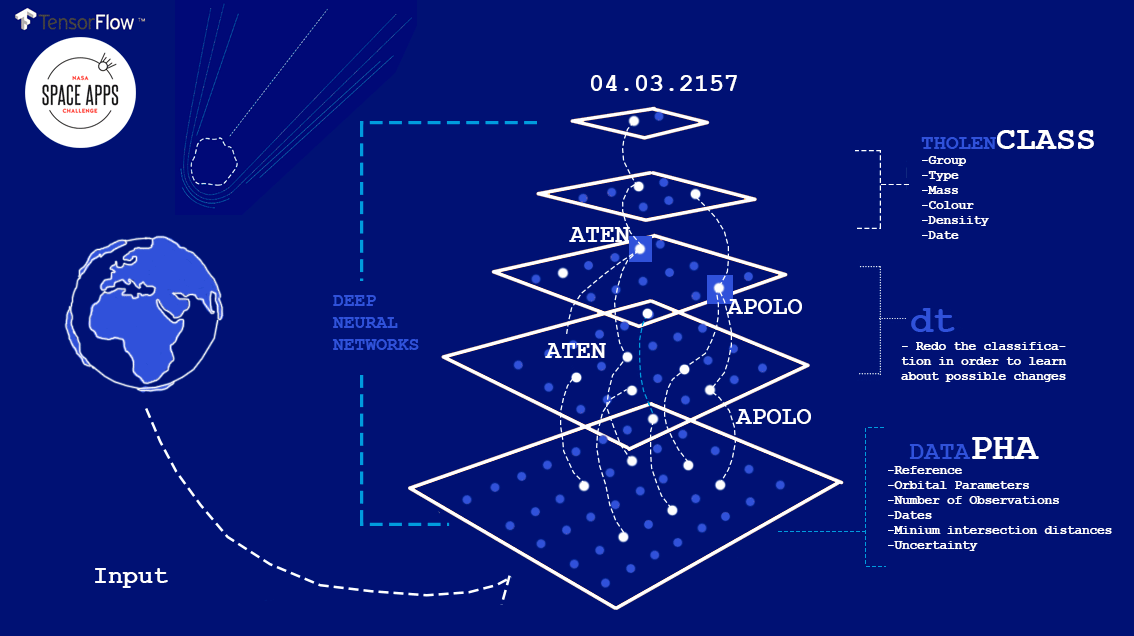
Captura del proyecto de Deep Asteroid, presentado a NASA Space Apps Challenge
Y ahora, varios años después ¿cómo crees que podríais haber mejorado vuestro modelo?
El proyecto de análisis a partir de los datos del dataset de NASA continuó y probamos diferentes frameworks y herramientas : tanto las nuevas versiones y arquitecturas de TensorFlow como modelos autorregresivos de predicción con un framework de Facebook, llamado Prophet. La interacción a diferentes frameworks permite encontrar patrones más precisos de impacto a lo largo del año.
Y quizá suena un poco frívolo pero ahora que todo el mundo habla de la película “Don’t Look Up”, me gustaría saber tu opinión al respecto en lo que se refiere al uso de los datos para calcular la colisión de un asteroide contra la Tierra. Qué hay de mito y qué hay de realidad en la película
Vi la película durante estas Navidades y me impactó. Creo recordar que al principio, en la conversación sobre el tema, se hablaba más de la ecuación del cálculo de trayectorias y no tanto de los datos. Los datos , bajo mi punto de vista, actúan en este caso como un test en la hipótesis de cálculo de trayectoria del impacto de asteroides
Pasemos ahora a otra de tus pasiones, el Desarrollo de videojuegos. en primer lugar me gustaría que me contaras de donde proviene esa pasión
Siempre me ha gustado jugar a videojuegos y supongo que viene por compartir la pasión con mi hermano. Recuerdo con cariño sobre todo la saga de Flipper en la megadrive, y Crash Bandicoot en la Play Station 1 .
Ahora los concibo de manera diferente y los disfruto a nivel narrativo y los concibo como puzzles encadenados que desarrollan un arco más genérico dentro de una historia. Durante los últimos años me interesan más los juegos indies y los serious games.
En alguna de tus charlas has destacado el papel de la IA en el desarrollo de videojuegos. ¿Cuáles han sido los grandes avances en este campo en los últimos años? Para que hagas una idea yo me quedé en las primeras etapas del SIM City, así que si te parece nos remontamos a esa época
La IA en videojuegos está presente en la industria desde los años 70 , desde la generación de niveles hasta el desarrollo de personajes no jugables que interaccionan con el jugador (NPCs) .
Con respecto a SimCity y los Sims, cabe destacar el uso de máquinas de estado y de las llamadas utility functions , que han jugado un papel fundamental en la generación de poblaciones o en cómo se comportan los personajes de los Sims. Desde el punto de vista del diseño de juego, aportan cierta estocasticidad que enriquece mucho la experiencia.
El avance en sí mismo de machine learning ha tenido impacto dentro de la industria de los videojuegos, y como prueba de ello es el uso de Deep Learning en la generación de niveles de manera automática y el avance en el diseño de NPCs.
Me gustaría profundizar ahora en Starcraft 2. Te he escuchado decir que Starcraft como un desafío para la IA. ¿En qué consiste este desafío? Por lo que tengo entendido, Deep Mind está tratando de conseguir en StarCraft algo parecido a lo que ya hizo con el ajedrez o con el Go. Es decir “derrotar a los humanos”
StarCraft 2 es un juego de estrategia en tiempo real desarrollado por Blizzard. Engloba una serie de características: control a gran (macro) y pequeña (micro) escala, observabilidad parcial, capacidad estratégica), etc. Eso supone un campo de cultivo interesante para el desarrollo de agentes y de puesta a prueba de las capacidades de los mismos.
Con respecto a los avances de Deepmind, tengo entendido que han desarrollado junto con Blizzard la API y el entorno de aprendizaje y publicado ya el paper en Nature en 2019 sobre la performance de su agente ( AlphaStar ). El desafío del StarCraft con lo relativo a agentes no es nuevo y la primera API está basada en la versión de Blood War. Si bien existen algunos agentes que han mostrado una buena performance con respecto a los humanos , la mayoría de las soluciones se basaban en IA de tipo simbólico, máquinas de estado u otras aproximaciones diferentes a AlphaStar.
¿Podrías detallar el enfoque metodológico que se está siguiendo en este proyecto de Deep Mind?
La investigación en torno a AlphaStar es bastante multidimensional, y sería un poco reduccionista reducirlo a un único desarrollo algorítmico : si hablamos de enfoque , pondría la analogía de una cadena. Primero entrenaron a un agente supervisado basado en aprendizaje por imitación un entrenamiento a través de replays de jugadas. A partir de ahí desarrollaron un sistema multiagente conocido como ‘AlphaStar ladder ‘ , en el que ponían a agentes a competir unos contra los otros. El proyecto también usa Redes Neuronales para procesar la información y producir las decisiones que toma el agente. Parte del equipo ha seguido y en el último NeuRIPS han publicado los avances utilizando nuevos algoritmos.
Y si miramos hacia el futuro ¿qué grandes avances crees que veremos en el desarrollo de IA para Games?
Creo que puede haber un avance significativo en la generación de contenido interactivo y en el desarrollo de NPCs que puedan interactuar de manera más personalizada con el jugador. Por supuesto, también creo que existen otros aspectos de automatización, como el testing, o la generación de escenarios, en las que se están viendo ya avances. Personalmente sigo el trabajo de la Startup Modl.ai , que se dedica con pasión a este tema.
Hablemos ahora de la otra cara de la moneda. El uso de juegos para mejorar la IA (Games for AI). ¿Podrías explicarme en qué consiste y mencionar algún ejemplo que consideres interesante?
La dicotomía de Games for AI VS AI for Games es un tema interesante en sí mismo. Con respecto al primero, los videojuegos actúan como un entorno seguro de entrenamiento de agentes previos a la aplicación en la industria . Van un punto más allá de las simulaciones de robots y ofrecen entornos complejos que ejemplifican desafíos que suponen pasos significativos en el desarrollo de la Inteligencia Artificial. Por supuesto , como ejemplos, la industria tiene el caso de los famosos videojuegos de Atari, y , por supuesto, el StarCraft.
Por tu parte, en el año 2020 comenzaste a desarrollar el videojuego Mempathy. Por lo que he leído has optado por un enfoque de Reinforcement Learning. ¿Puedes detallar exactamente qué modelos has usado y por qué has optado por ellos?
Mempathy es un juego narrativo de point and click. Una conversación con un agente ( NPC ) dentro de un grafo de constelaciones . He experimentado con diversas técnicas de machine learning, teniendo como objetivo enriquecer la conversación y hacerla creíble ,única y segura.
Para ello, empecé comparando técnicas de aprendizaje por refuerzo ( entrenar un agente basado en un sistema de recompensas ) y aprendizaje por imitación (darle muchos ejemplos de conversación y dejar que fuese el agente el que crease el contenido ) . Estos experimentos jugables fueron publicados y compartidos con la comunidad en el workshop de EXAG AIIDE 2020 y en el workshop de ‘NeuRIPS : When language meets games’
Durante 2021, enfocandome en crear una experiencia narrativa diversa, me pase a modelos GPT, si bien comentar que la implantación que he seguido se basa en un modelo tuneado mas la implantación de Plug and Play Models, discriminadores.

Capturas del gameplay de Mempathy , proyecto de juego narrativo para mobile.
Si salimos del mundo de los videojuegos, ¿qué casos de uso de Reinforcement Learning te parecen más fascinantes? ¿Y de GPT?
El aprendizaje por refuerzo ya ha visto algunos casos de uso como en motores de recomendación, y por supuesto, en robótica y coches autónomos. En el caso de GPT , asistentes virtuales que puedan ayudar a generar contenido o chatbots a modo de customer service , pueden, a su vez, ser más útiles.
¿Qué limitaciones existen para que la adopción de Reinforcement Learning sea mayor fuera del ámbito de los juegos? ¿Y de GPT?
Con respecto al aprendizaje por refuerzo, la construcción de entornos lo suficientemente ricos como para que los agentes funcionen bien durante la fase de producción. También, desde el punto de vista técnico, el correcto diseño del espacio de acciones y observaciones.
Desde el punto de vista de GPT , la producción de contenido seguro y beneficioso , así como evitar o mitigar el posible uso malicioso ( spam ) son aspectos importantes a la hora de la implantación en la industria. El tema de que estos modelos de languages esten en ingles, es algo que también afecta a la adopción genérica para casos de uso multi-idioma.
Y si hablamos de Deep Learning ¿qué casos de uso te parecen más interesantes?
Cuando se indaga a más bajo nivel sobre Deep Learning existe un cambio de paradigma, al poder ser concebido en sí mismo como una función de optimización: ha sido interesante ver casos de uso tanto en banca como en salud , aunque la de visión en coches autónomos sigue siendo la que más me llama la atención. Si bien es cierto que hay que tener en cuenta que para que esta técnica funcione se necesitan cantidades ingentes de datos .
En algunas ocasiones los proyectos de Deep Learning y de Reinforcement Learning se enfocan como puros retos de programación. Yo creo que es un error porque hay todo un trabajo de conceptualización, definición, etc que no se puede obviar. Me gustaría saber tu opinión al respecto (puedes llevarme la contraria) y que me contaras también qué perfiles / roles son necesarios para que tipo de proyectos lleguen a buen puerto
Desde su concepción y más a bajo nivel, hay varios desafíos tanto en el aprendizaje profundo como el de imitación, tales como optimización y control .
Desde el punto de vista de la aplicación a industria , tanto stakeholders como técnicos tienen un papel que jugar : entender bien los datos y que técnica debe de utilizarse para cada problema es clave, así como alinear a todo el mundo presente en la solución en tiempos y soluciones.
Sobre los roles, supongo que depende del grado de madurez del proyecto, la propuesta , y los datos.
¿Cómo te mantienes al día de los avances en el campo de la Inteligencia Artificial?
Leyendo papers sobre temas de investigación que me interesan, siguiendo la actividad de laboratorios concretos , y asistiendo a seminarios y conferencias. El mundo de la Inteligencia artificial dentro de la investigación es bastante amplio, así que también es importante enfocarse en una serie de temas para alcanzar una profundidad rigurosa
Una de las críticas habituales a algunos modelos de IA es la falta de transparencia y los posibles sesgos y discriminaciones que incorporan. ¿Cómo crees que podemos asegurar que nuestros proyectos de IA cumplen unos requisitos de éticos de no discriminación?
Este tema es importante y no debería de pasar desapercibido. Desde el punto de vista técnico, el desarrollo de métricas estadísticas que puedan medir el sesgo , el análisis de los datos de entrenamiento, y la construcción de herramientas que evalúen posibles discriminaciones y sesgos pueden ser clave desde el punto de vista técnico. Desde el punto de vista institucional , la existencia de compañías y organismos reguladores que puedan evaluar estos aspectos es importante.
Y ya que hablamos de discriminaciones, un tema que me preocupa es la falta de mujeres en el mundo de Data en particular y STEM en general. ¿Qué podemos hacer para reducir este GAP?
Es un desafío multidimensional que requiere esfuerzos de todos y de todas. Siempre aconsejo para estos casos seguir el white paper de la fundación de Anita Borg para entender el desafío y tomar medidas maduras con respecto a este tema.
Recientemente entrevisté a Enrique Mora (AI Sr. Solutions Architect en Nestlé) y le pedí que hiciera una pregunta para la siguiente persona a entrevistar. Su pregunta fue “¿Cuánto crees que tardará la IA/ML en penetrar en todos nuestros ámbitos del dia a dia?”
La IA ya está presente en ámbitos de nuestra vida , tanto en la búsqueda como en el filtrado y en los motores de recomendación. No me atrevería a dar un tiempo concreto para “todos los ámbitos de nuestra vida “. Quizá lo interesante es preguntarse si debe de estar presente en todos. Pese a mi entusiasmo a largo plazo con respecto a la Inteligencia artificial , espero que sea la inteligencia humana la que siempre esté presente, y que sea la Inteligencia Artificial la que pueda ayudarnos en aspectos para completarnos o ayudarnos a solventar problemas.
Y tú qué le preguntarías al siguiente entrevistado
¿Qué tipo de modelos predictivos y soluciones de machine learning pueden ser útiles para e-sports ?